$\require{cancel}$
Unicode
- Reference.
- Unicode is the "new" standard for character encoding.
- New as in the first version of the standard was issued in 1991
- We are currently on version 16 (9/2024), with version 17 in the works
- Unicode is a 8 (UTF-8), 16 (UTF-16) and 32 (UTF-32) bit standard.
- All characters can be represented in 32 bits.
- And is based on the ASCII.
- In fact, the ASCII table is first "table" in unicode
- see This reference
- In HTML &#xnnnn; will display a unicode character
- G is hex 47 (G)
- Look at the list of Character sets supported
- The Greek letters are 037016 to 03ff16
- see this chart
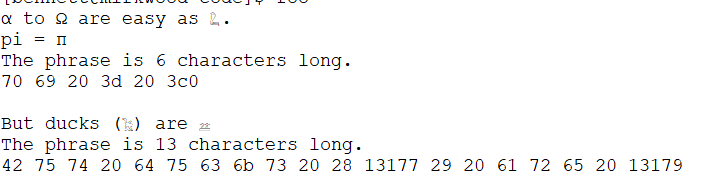
- And cover α to Ω
- Note just like ASCII, Upper case letters, then lower case letters in order.
- I can't type this up without some 𓅹 𓂀 Hieroglyphs!
- The standard includes
- 135,000 characters in use
- 800,000 unused characters
- 6,400 for private use
- Some characters are used for composition
- This: ü is a composition of u and ̈
- There are three encoding forms, UTF-8, UTF-16 and UTF-32
- We have been looking at UTF-16
- But all forms require at most 4 bytes to represent any character.
- It is more complex to use in a language like c++, but that is not our problem now.