Tidy Data
- An important article seems to be by Hadley Wickham
- H. Wickham, "Tidy Data", Journal of Statistical Software,vol. 59, no. 10, Feb. 2014.
- Some points
- Data Scientists spend an immense (80%) of time cleaning data.
- Tidying: An aspect of cleaning data. The act of structuring datasets to facilitate analysis.
- He proposes a standard way to organize data to make the initial cleaning of data easier.
- You are fairly lucky, as much of this work has been done in most datasets you see.
- His principles are "closely tied" to database's relational algebra.
- He seems to indicate that this paper is just refraiming these principles from database.
- Based on his experiences
- Used to develop R's Tidyverse
- Datasets
- Datasets are usually rectangular tables.
- Columns are labeled
- Rows are sometimes labeled.
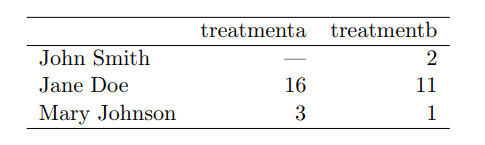
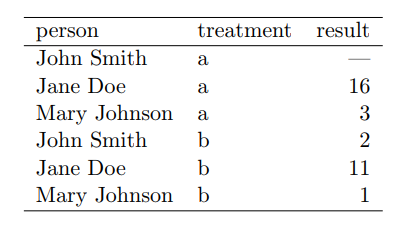
- He shows a small dataset three ways
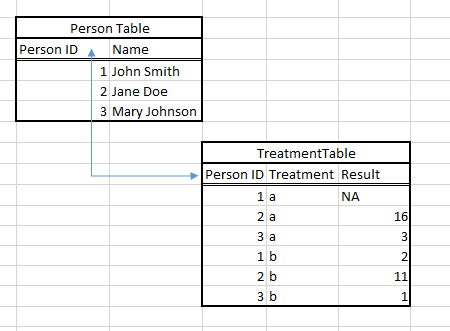
- By the way, a databse would probably organize the data like this
- Datasets are composed of
- Values: numbers or strings
- Variables: are a collection of values witch measure the same underlying attribute across units.
- These become columns in tidy data.
- I will likely call these fields.
- Observations are a collection o fall values measured on the same unit across all attributes.
- These become rows in tidy data.
- I will likely call these records.
- He argues that it is easy in practice to define what the observations and variables are.
- But it is more difficult to come up with a generic definition.
- A dataset may contain multiple levels of observations
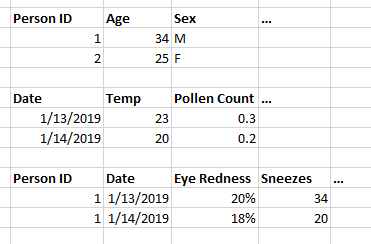
- Example: allergy study
- Demographic data for each person
- Meteorological data for each day
- Medical data for each person for each day
-
- He defines tidy data as
- Each variable forms a column
- Each observation forms a row
- Each type of observational unit forms a table.
- He claims this is Codd's third normal form.
- I don't quite believe that, but ok.
- Tidy data, he claims
- Makes it easy to extract needed variables.
- Well suited for analysis because data related to a single observation are paired.
- He goes on to provide a number of examples of non-tidy data and how to transform them into tidy data.
- Column headers are data, not labels.
- This one is tricky.
-
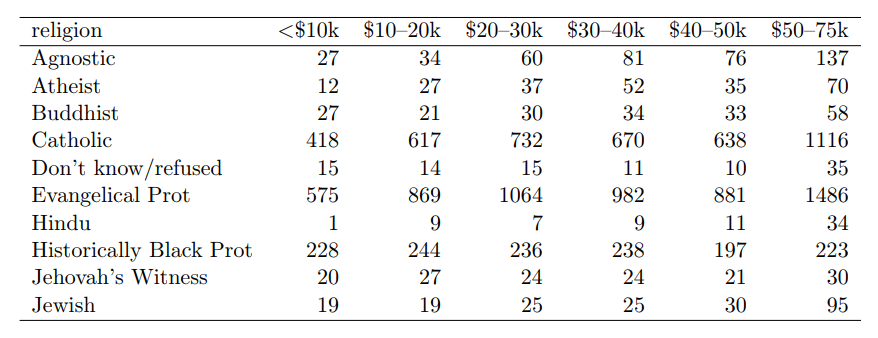
- The salary range is actually data.
- He suggests
-
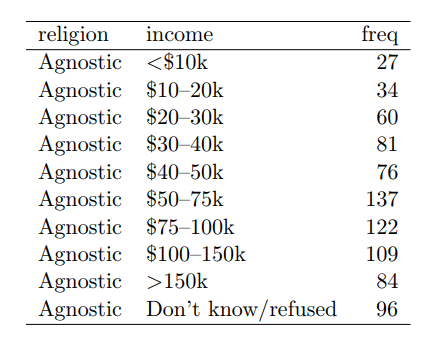
- He really doesn't want multiple columns for the same variable.
- His format is better for vector operations.
- The original is better for matrix operations.
- Think what would happen to the table if more variables, like duration of service, were added to the table.
- Multiple variables are stored in one column
-
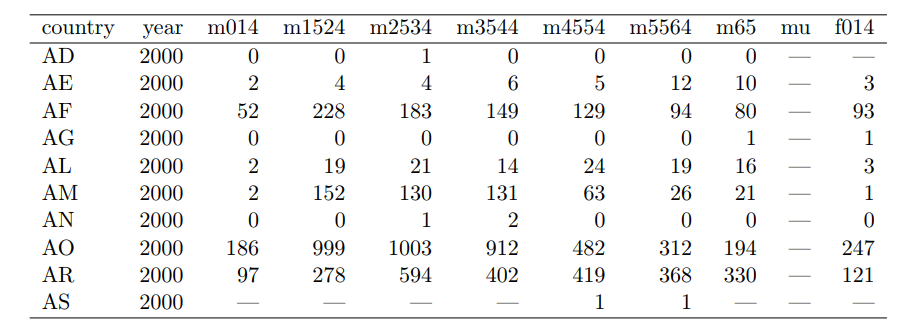
- This is a tuberculosis datset.
- m014 means males 0-14,... mu - male unknown.
- A first breakdown (eliminating the fact that both gender and age group are variables) leads to
-
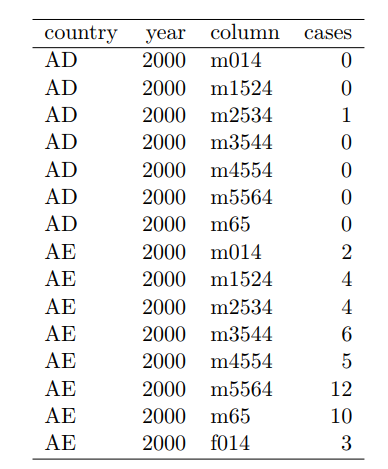
- But the "column" column contains two variables, age range and gender.
- He suggests
-
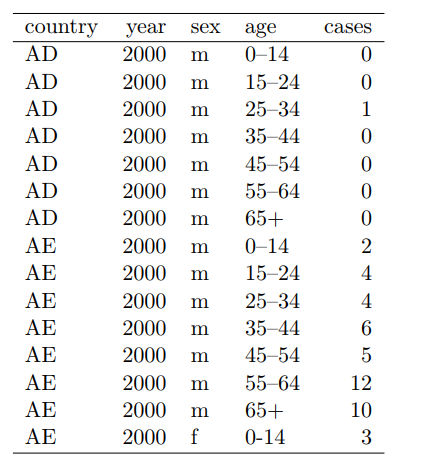
- It would be easy to add populations to the last table, but far more difficult to add populations to the first.
- Variables are stored in both rows and columns
-
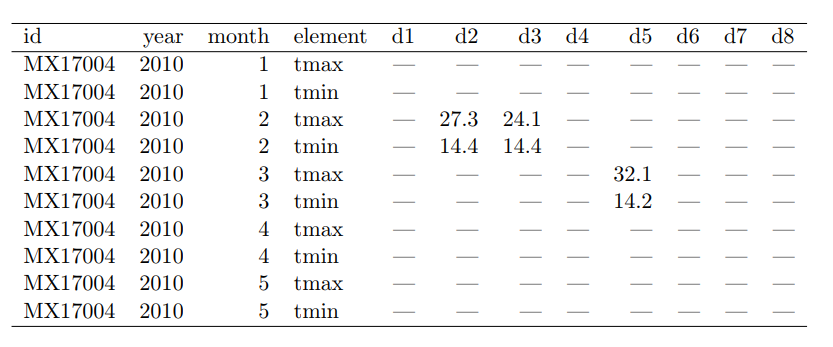
- Weather data
- d1 ... d31 the day of the months, data, not column headings.
- d31 is unused on 1/2 of the months.
- tmin-tmax are column headings, not data.
- Solution
-
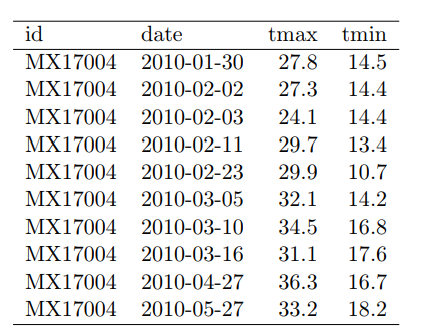
- Multiple types of observational units are stored in the same table
-
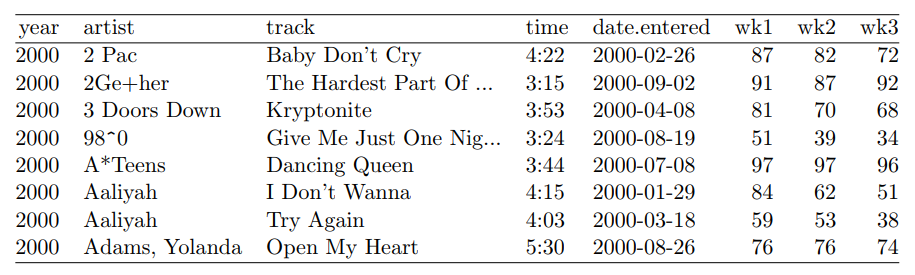
- Information about a song (time, artist, title, year)
- And information about the ranking of that song wk1, wk2, ...
- This really represents two different tables.
-
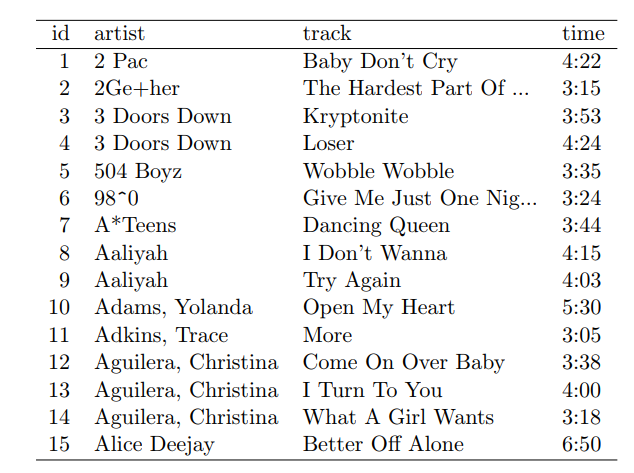
-
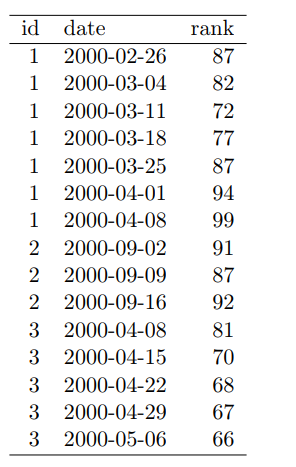
- A single observational unit is stored in multiple tables.
- The babynames database is spread across many files.
- Each contains names and ranks
- Tidy version
-
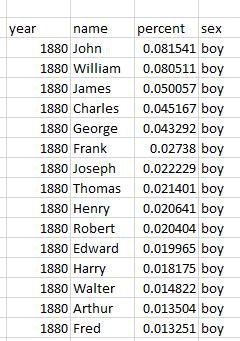
- He provides a description of tidy tools
- He has a case study
- Since his data is tidy, he is mostly demonstrating "tidy tools"
- He has a final summary