Memory Latency Activity
For this activity you will compute the impact of memory latency on the CPI and the speed of your program. For this activity, you will use my implementation of the Insertion Sort. Download this sort here
There are two related constants you may wish to change in this program. They are Size the size of the array measured in elements, and Array the number of bytes in the array. Array should be Size * 4.
Some MARS tools slow computations down incredibly. You should reduce the number of elements in the array when told to do so, however for cache analysis, you should use an array with 250 elements.
- Begin by creating a spreadsheet.
- In the first sheet place your name, and the fact that this is homework 10.
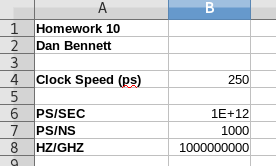
- Build a table of the following assumptions:
- Clock Speed (ps) : 250
- PS/SEC : 1E12
- PS/NS: 1000
- HZ/GHZ : 1E9
-
- For computations in this worksheet, you will show units for a computation by placing the units above the value entry.
- For example, we will compute the GHz rating for this machine.
- In cell A11 place the Label Clock Speed (GHz)
- In cell B10 place the label cycles/ps
- In cell B11 compute this value (=1/B4)
- In cell C10 place the label ps/sec
- In cell C11 compute this value (=b6)
- In cell D10 place the label GHz/Hz
- In cell D11 compute this value (=1/B8)
- In cell E10 place the label GHz
- In cell E11 compute the value by multiplying the values in the previous cells.
-

- Memory Latency (ns) in Cell A13- C13
- Read the wikipedia article on latency. Compare this with the information presented in this paper. From the two select a memory latency for your model.
- Make sure you use the true access time, not the CAS latency
- Note the memory type selected and the source.
-
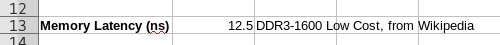
- Cache miss penalty (cycles) A15-E16
- We want to have this in terms of CYCLES so we can add it to our CPI computation.
- This is based on the ns/miss (the memory latency from above)
- and the constants ps/ns and cycles/ps
-

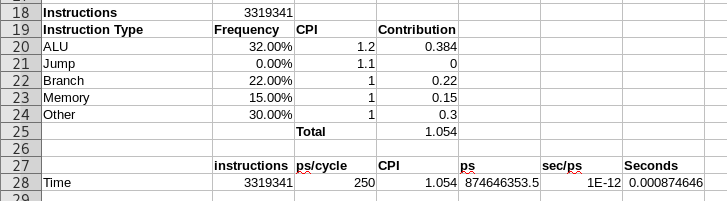
- Using the Instruction Statistics tool in Mars, compute the number of instructions required and the instruction mix to sort 250 numbers using the insertion sort program
- Start the tool and Connect to MIPS
- Run the program from the beginning.
-

- Add a line for number of instructions. Use the value 3,319,341, which is that number of instructions needed to sort 1000 numbers.
- You can compute this number if you wish, but it will take a while.
- Add these statistics in a table.
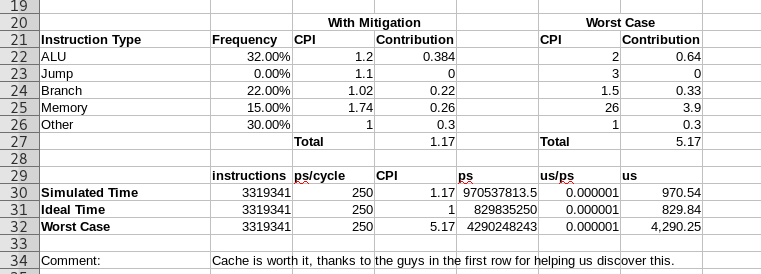
- For now hard code the cpi for each instruction type to be that given in the picture.
- Compute the contribution of each instruction type and the total CPI for the machine.
- Compute the time required for your program as shown.
-
- Add a worksheet to compute the CPI for the branch instructions.
- (A little + sign at the bottom of most spreadsheet programs.)
- Name this Branch CPI
-
- Make sure that you have only 250 elements in the array.
- Start the BHT Simulator tool.
- Set the BTH history size to be 1
- You only need 8 entries in the table.
- Connect, and rerun the program.
-
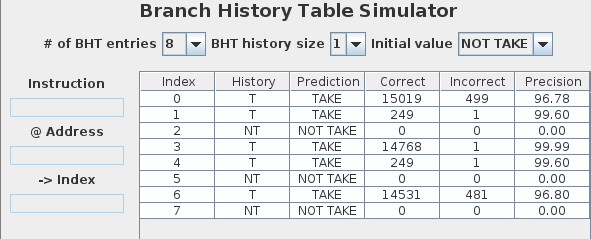
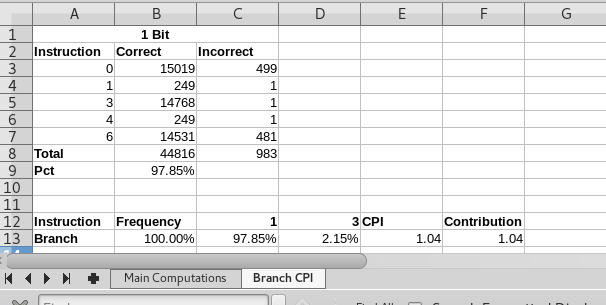
- Construct a table in your worksheet to compute the CPI for branch instructions for this program.
- Transfer the table from the simulator into your worksheet.
- Compute the total percent.
- Assume a mispredicted branch costs 3 cycles.
- Compute the CPI for a branch.
-
- Link this CPI computation back into your computation on the first worksheet.
- Build a second table on this worksheet for 2 bit branch prediction.
- Make a comment about the difference between 1 bit and 2 bit branch prediction.
- Add a worksheet to compute the CPI for load instructions.
- You will use the Data Cache Simulator tool
- This tool runs much faster, so we can increase the number of elements in the array to 500 (Array size 2000).
- The array will be 2000 bytes.
- Start a worksheet labeled Cache Data
- First let us explore the different cache block size options for 256 bytes of cache.
- Select direct mapped cache.
- Select LRU for the replacement policy.
- Set size is 1.
- We will range the number of blocks fro 64 to 1
- We will change the block size from 1 to 64 to keep the cache size fixed.
- 64-1 means there are 64 cache locations, each hold 1 word.
- 16-4 means that there are 16 cache locations each holding 4 words.
- The following is a simulation of 64-1
-
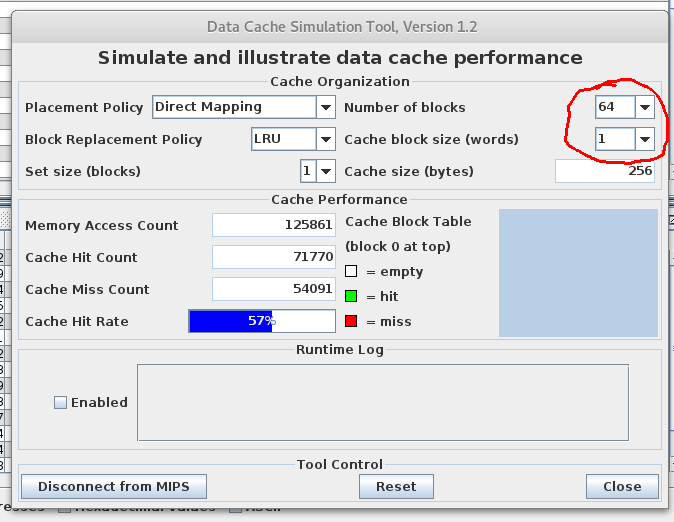
- Construct the following table by recording cache misses in the appropriate table.
-
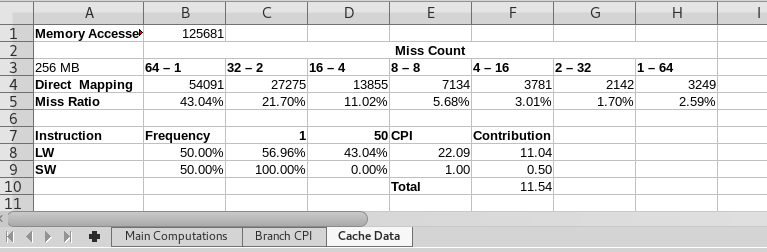
- C8 should be 1-D8
- D8 should be a value from the miss ratio row above.
- D7 should be a link back to the cycles/miss on the main table.
- Insert a comment discussing where the cache behaves the best and why.
- Now explore the impact of cache size.
- Build a second table
- Keep the block size fixed at 4.
- Use the Fully Associative placement policy
- Range the number of blocks from 8 to 128 blocks.
- Build a table with
- One row with LRU replacement policy
- Build three rows with random replacement policy.
(It should really be more than 3 rows, but the data really should be collected by an automated tool)
-
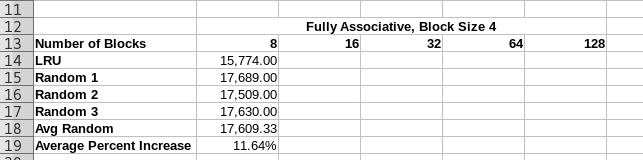
- You should complete the above table.
- Answer the following questions below this table.
- Why is 128 blocks always the same and so small?
- What is the impact of increased cache size on performance.
- What is the cost of random replacement.
- Update the table on the fist page
- Include the new CPI for Memory instructions
- Change the time to be in μs.
- Add a line that computes the perfect time for this program, assuming a CPI of 1.
- Add a line that computes the worst possible time for this progra, no hazard mitigation or cache
- ALU CPI as in class
- Branch CPI as in class
- LW takes the the full cache miss penalty.
- Add a comment discussing the final results.
- Save this worksheet and submit it to your instructor.