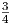 . This is an example of an in line math
equation. It does not have a reference number or anything like it. It is just a
fraction sitting the middle of a paragraph for some reason.
. This is an example of an in line math
equation. It does not have a reference number or anything like it. It is just a
fraction sitting the middle of a paragraph for some reason.
Cluster Analysis Annotated Bibliography
Dan Bennett
CSCI 480
September 19, 2017
This is an example annotated bib. It is not well written at this point. It is more for demonstration purposes.
By the way, the tex file was taken from http://math.ucdenver.edu/\textasciitildebillups/courses/ma5779/annotated\_bibliography.html
You can do math if you wish: . This is an example of an in line math
equation. It does not have a reference number or anything like it. It is just a
fraction sitting the middle of a paragraph for some reason.
The following is a an example of an equation that is not part of a paragraph. Notice that it does have a number, and you could add reference, see equation 1.
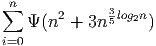 | (1) |
You did not learn how to do this fraction in [2].
[1] John A Hartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm. Journal of the Royal Statistical Society. Series C (Applied Statistics), 28(1):100–108, 1979.
This article is a published version of the algorithm. It provides code to execute k-means cluster analysis. This provides a benchmark for other implementations.
[2] Anil K Jain. Data clustering: 50 years beyond k-means. Pattern recognition letters, 31(8):651–666, 2010.
A nice summary of the state of the art of data clustering at the time of publication. Many citations.
[3] Tapas Kanungo, David M Mount, Nathan S Netanyahu, Christine D Piatko, Ruth Silverman, and Angela Y Wu. An efficient k-means clustering algorithm: Analysis and implementation. IEEE transactions on pattern analysis and machine intelligence, 24(7):881–892, 2002.
This is an old document, but it has a very nice write up and has been cited many times. The emperical section has good results and it would be very interesting to attempt to reproduce.